Google no acaba de publicar Magika desde cero, pero su herramienta de identificación de archivos ha vuelto al centro de la conversación tecnológica por una razón muy concreta: en un mundo donde los agentes de Inteligencia Artificial leen, abren, resumen, transforman y ejecutan archivos de forma cada vez más autónoma, saber qué tipo de archivo se tiene delante ya no es una comprobación menor.
Magika es un detector de tipos de archivo basado en aprendizaje profundo. Su trabajo no consiste en decir si un fichero es malicioso, ni en sustituir a un antivirus, ni en hacer análisis forense completo. Responde a una pregunta más básica, pero decisiva: qué contiene realmente este archivo. Google lo usa a escala para ayudar a enrutar ficheros de Gmail, Drive y Safe Browsing hacia los sistemas adecuados de seguridad y políticas de contenido, procesando cientos de miles de millones de muestras cada semana, según la documentación del propio proyecto.
Por qué identificar bien un archivo importa más que nunca
Durante décadas, la identificación de archivos ha dependido en buena medida de extensiones, cabeceras, “magic bytes” y reglas escritas a mano, como las usadas por herramientas clásicas del entorno Unix. Ese enfoque sigue siendo útil, pero tiene límites claros. Un archivo puede llamarse factura.pdf y no ser un PDF. Un script puede llegar disfrazado como imagen. Un fichero políglota puede comportarse de forma distinta según la herramienta que lo procese. Y muchos lenguajes de programación o formatos de configuración se parecen demasiado para que una regla simple los distinga bien.
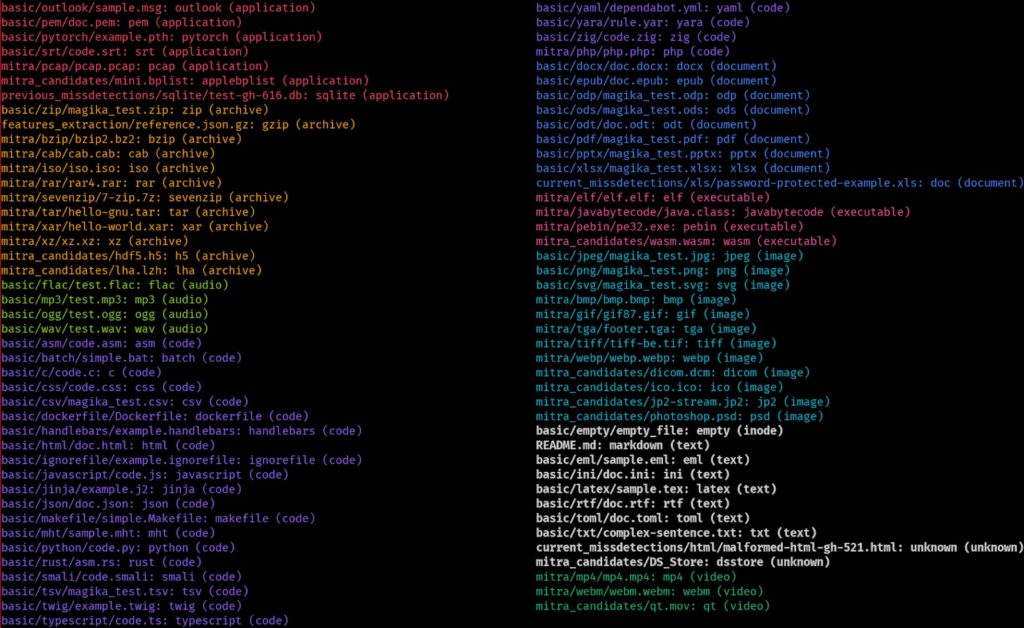
Magika cambia el enfoque. En lugar de basarse solo en patrones escritos manualmente, usa un modelo de Inteligencia Artificial compacto y optimizado para clasificar el contenido. Google afirma que la herramienta ha sido entrenada y evaluada con unos 100 millones de muestras repartidas entre más de 200 tipos de contenido, tanto binarios como textuales, y que alcanza una precisión media cercana al 99 % en su conjunto de prueba. La inferencia, una vez cargado el modelo, ronda los 5 milisegundos por archivo incluso en una sola CPU.
La cifra de velocidad es importante. Un detector de tipos de archivo no puede ser lento si se quiere integrar en pasarelas de correo, repositorios, sistemas de subida de documentos, herramientas de análisis de malware o agentes que trabajan con cientos de ficheros. Magika está pensada para ejecutarse localmente, sin depender de una llamada de red ni de una GPU, y con un tiempo de análisis casi constante respecto al tamaño del archivo, porque solo usa una parte limitada de su contenido.
El salto de Magika 1.0, anunciado por Google en noviembre de 2025, refuerzó esa dirección. La versión estable amplió la cobertura a más de 200 tipos de archivo, añadió una nueva implementación de alto rendimiento en Rust, mejoró la detección de formatos textuales complejos y renovó los módulos para Python y TypeScript. Entre los nuevos formatos aparecen ficheros relevantes para ciencia de datos, desarrollo, DevOps, bases de datos, gráficos y modelos de aprendizaje automático, como Jupyter Notebook, PyTorch, ONNX, Parquet, Dockerfile, TOML, HCL, YARA, SQLite o WebAssembly.
La capa defensiva que necesitan los agentes
El interés actual por Magika no se explica solo por su rendimiento. Se explica por el auge de los agentes de Inteligencia Artificial. A diferencia de un chatbot tradicional, un agente puede leer repositorios, abrir archivos adjuntos, modificar código, ejecutar comandos, consultar herramientas externas o encadenar acciones. En ese escenario, cada fichero que toca puede convertirse en una entrada no confiable.
El problema no es teórico. En febrero de 2026, Check Point Research detalló vulnerabilidades críticas en Claude Code que podían permitir ejecución remota de código y robo de credenciales mediante configuraciones maliciosas incluidas en repositorios. El vector pasaba por mecanismos como hooks, servidores MCP y variables de entorno, activados al clonar y abrir proyectos no confiables.
En marzo de 2026, CERT/CC publicó también un aviso sobre cuatro vulnerabilidades en CrewAI, con riesgos que incluían ejecución remota de código, lectura arbitraria de archivos y SSRF. Una de ellas estaba vinculada directamente a la herramienta Code Interpreter, mientras que otras derivaban de configuraciones por defecto inseguras en el agente principal y sus imágenes Docker asociadas.
Estos casos muestran una realidad incómoda: cuando una herramienta de Inteligencia Artificial tiene acceso al sistema de archivos, a intérpretes de código o a comandos de shell, la frontera de confianza cambia. Ya no basta con analizar el prompt. También hay que validar qué archivos se abren, qué contienen, qué extensión dicen tener, qué tipo real detecta el sistema y qué herramienta va a procesarlos después.
Magika encaja ahí como una primera barrera. No decide si un archivo es seguro, pero puede ayudar a evitar que un agente trate un ejecutable como texto, un script como imagen o un archivo de configuración como un documento inofensivo. En un flujo bien diseñado, esa clasificación debería alimentar reglas de seguridad: qué se puede abrir, qué debe aislarse, qué requiere sandbox, qué se rechaza y qué se manda a un análisis más profundo.
Código abierto, Rust y un estándar compartido
Google publicó Magika como proyecto de código abierto bajo licencia Apache 2.0 y lo mantiene en GitHub. La herramienta está disponible como cliente de línea de comandos escrito en Rust, como API de Python y con bindings para Rust, JavaScript/TypeScript y Go en evolución. La demo web, además, se ejecuta localmente en el navegador, lo que permite probarla sin enviar archivos a un servidor externo.
La reescritura en Rust tiene sentido para un componente de seguridad. Rust ofrece buen rendimiento, gestión segura de memoria y facilidad para distribuir binarios nativos. En herramientas que se ejecutan en servidores, estaciones de trabajo de analistas, pipelines CI/CD o sistemas de entrada de archivos, reducir dependencias y errores de memoria importa tanto como la precisión del modelo.
La adopción también empieza a darle peso como estándar de facto. Google indica que Magika ya está integrado en VirusTotal y abuse.ch, dos referencias habituales para equipos de seguridad y análisis de amenazas. Esa integración puede ayudar a que distintas herramientas hablen un lenguaje más coherente al describir tipos de archivo, algo útil cuando se comparten indicadores, muestras o resultados entre sistemas.
Para administradores y equipos de seguridad, el valor está en que Magika puede incorporarse como una pieza pequeña dentro de procesos existentes. Puede ejecutarse en línea de comandos, analizar directorios de forma recursiva, integrarse en scripts, pipelines de subida, pasarelas de correo, sistemas de DLP, revisiones de repositorios o validadores previos antes de entregar un archivo a un agente.
No es un antivirus, pero puede evitar errores caros
La principal confusión que conviene evitar es pensar que Magika detecta malware. No lo hace. Un PDF puede ser realmente un PDF y aun así contener un exploit. Un documento Office puede estar bien clasificado y seguir incluyendo macros peligrosas. Un ZIP puede ser legítimo o formar parte de una cadena de ataque. Magika no sustituye a un sandbox, a un EDR, a un motor antivirus, a YARA ni a un análisis dinámico.
Su papel es anterior. Si se identifica mal el tipo de archivo, todo lo demás puede fallar. Un sistema puede aplicar el escáner equivocado, permitir una acción que debería bloquearse o mandar un fichero a un parser vulnerable. En seguridad, muchas cadenas de ataque empiezan por una suposición incorrecta. Magika intenta reducir ese margen de error.
También hay límites prácticos. Aunque Google ha entrenado el modelo con una base de datos enorme, ningún detector será perfecto. Los formatos raros, corruptos, deliberadamente manipulados o diseñados para confundir clasificadores seguirán existiendo. Por eso la propia herramienta incluye un sistema de umbrales por tipo de contenido: si la confianza no alcanza el nivel requerido, Magika puede devolver una etiqueta genérica como “documento de texto genérico” o “datos binarios desconocidos” en lugar de forzar una clasificación dudosa.
Ese diseño es acertado. En seguridad, decir “no estoy seguro” suele ser mejor que equivocarse con demasiada confianza. Un resultado desconocido puede enviarse a revisión o a un entorno aislado. Un falso positivo puede abrir la puerta a que el sistema trate un archivo peligroso como si fuera inocuo.
Magika llega en un momento en el que la infraestructura defensiva de la Inteligencia Artificial agéntica aún está en construcción. Los agentes ya leen correos, repositorios, documentos, hojas de cálculo, imágenes, PDFs, logs y archivos comprimidos. Muchos lo hacen con permisos amplios y en entornos donde el usuario espera productividad, no fricción. La seguridad tendrá que añadirse por capas: permisos mínimos, sandboxing, validación de entradas, control de herramientas, registro de acciones y detección precisa de tipos de archivo.
Ahí es donde una herramienta pequeña puede tener mucho impacto. Magika no resuelve por sí sola la seguridad de los agentes, pero sí aporta una pieza que faltaba: una forma rápida, local y precisa de saber qué archivo se está manejando antes de decidir qué hacer con él. En la era de la Inteligencia Artificial que actúa, no solo responde, esa primera pregunta vuelve a ser esencial.
Preguntas frecuentes
¿Qué es Magika?
Magika es una herramienta de Google de código abierto que usa aprendizaje profundo para identificar tipos de archivo a partir de su contenido.
¿Magika detecta virus o malware?
No. Magika no es un antivirus ni un detector de amenazas. Su función es identificar el tipo real de un archivo para que otros sistemas puedan aplicar el análisis adecuado.
¿Por qué es importante para la Inteligencia Artificial agéntica?
Porque los agentes abren, leen y procesan archivos de forma cada vez más autónoma. Si no identifican bien qué tipo de archivo manejan, pueden enviarlo al parser equivocado o ejecutar flujos inseguros.
¿Se puede usar fuera de Google?
Sí. Magika es de código abierto y está disponible como herramienta de línea de comandos, API de Python y bindings para otros lenguajes, además de una demo web que se ejecuta localmente en el navegador.